随着人工智能技术的飞速发展,尤其是ChatGPT等大模型应用的崛起,未来世界的数据呈爆发式增长,海量数据的处理对芯片的算力和能量效率提出了严峻挑战。然而,高能效计算芯片的发展正遭遇芯片架构、晶体管性能两个重大瓶颈:传统的冯诺依曼架构已经无法满足高速、高带宽的数据搬运和处理需求,未来的高能效运算芯片必须在硬件架构上进行革新,以适用于神经网络等模型的张量数据运算。与此同时,构建芯片的硅基互补金属氧化物半导体晶体管,也进入了尺寸缩减、功耗剧增的困境,亟需发展超薄、高载流子迁移率的半导体作为沟道材料,期望构建比硅基CMOS晶体管具有更好可缩减性和更高性能的晶体管。碳纳米管具有优异的电学特性和超薄结构,碳纳米管晶体管已经展现出超越商用硅基晶体管的性能和功耗潜力,因此有望成为构建未来高效能运算芯片的主要器件技术。只有在系统架构和底层晶体管两个方面共同实现突破,才能最大化地提升芯片的算力和能效。目前成熟的硅基器件技术的运算芯片主要依赖于架构的创新,而基于新材料电子器件的研究,主要集中在提升晶体管的性能,尚未有研究工作将二者结合起来。
宝威体肓官网、碳基电子学研究中心彭练矛院士-张志勇教授联合课题组,基于碳纳米管晶体管这一新型器件技术,结合高效的脉动阵列架构设计,成功制备了世界首个碳纳米管基的张量处理器芯片(如图1),可实现高能效的卷积神经网络运算。
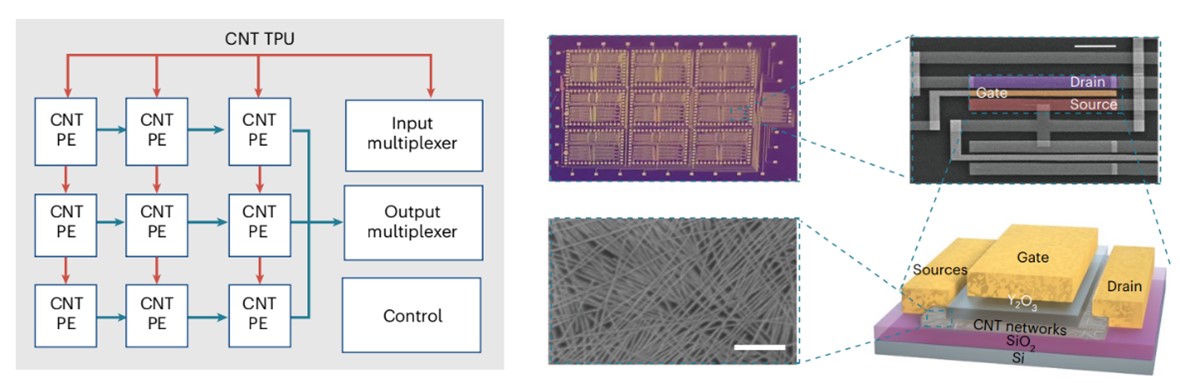
图1 基于碳纳米管晶体管构建的张量处理器
该芯片采用2bit MAC(乘累加单元),3微米工艺技术节点,共集成了3000个碳基晶体管,可实现图像轮廓识别、提取等功能,图像轮廓提取正确率高达100 %(如图2)。

图2 图像轮廓提取结果
通过脉动阵列架构设计,芯片可实现高效地数据复用(如图3),大大节约了张量运算所需的数据存储、搬运等操作,精准匹配了神经网络的运算特点。
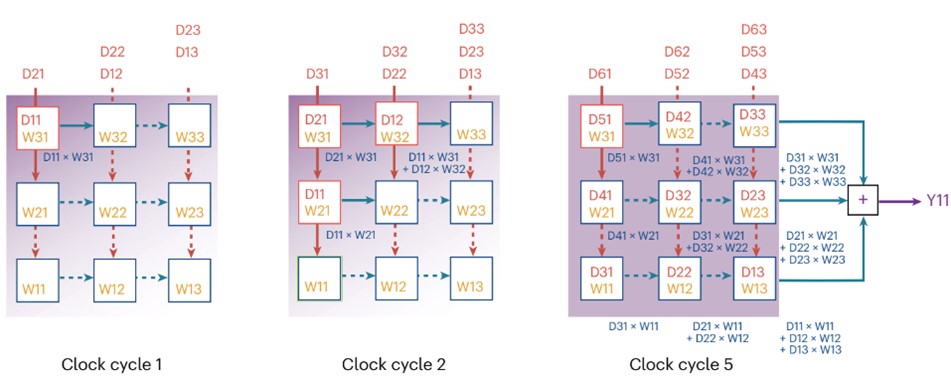
图3 脉动阵列架构与数据流设计
在此基础上搭建了5层卷积神经网络,实现了手写数字识别的应用,其理论正确率90 %,实际正确率可达86 %,与此同时,该芯片的功耗仅为295 µW,器件总数也为新型卷积加速硬件中的最低值。
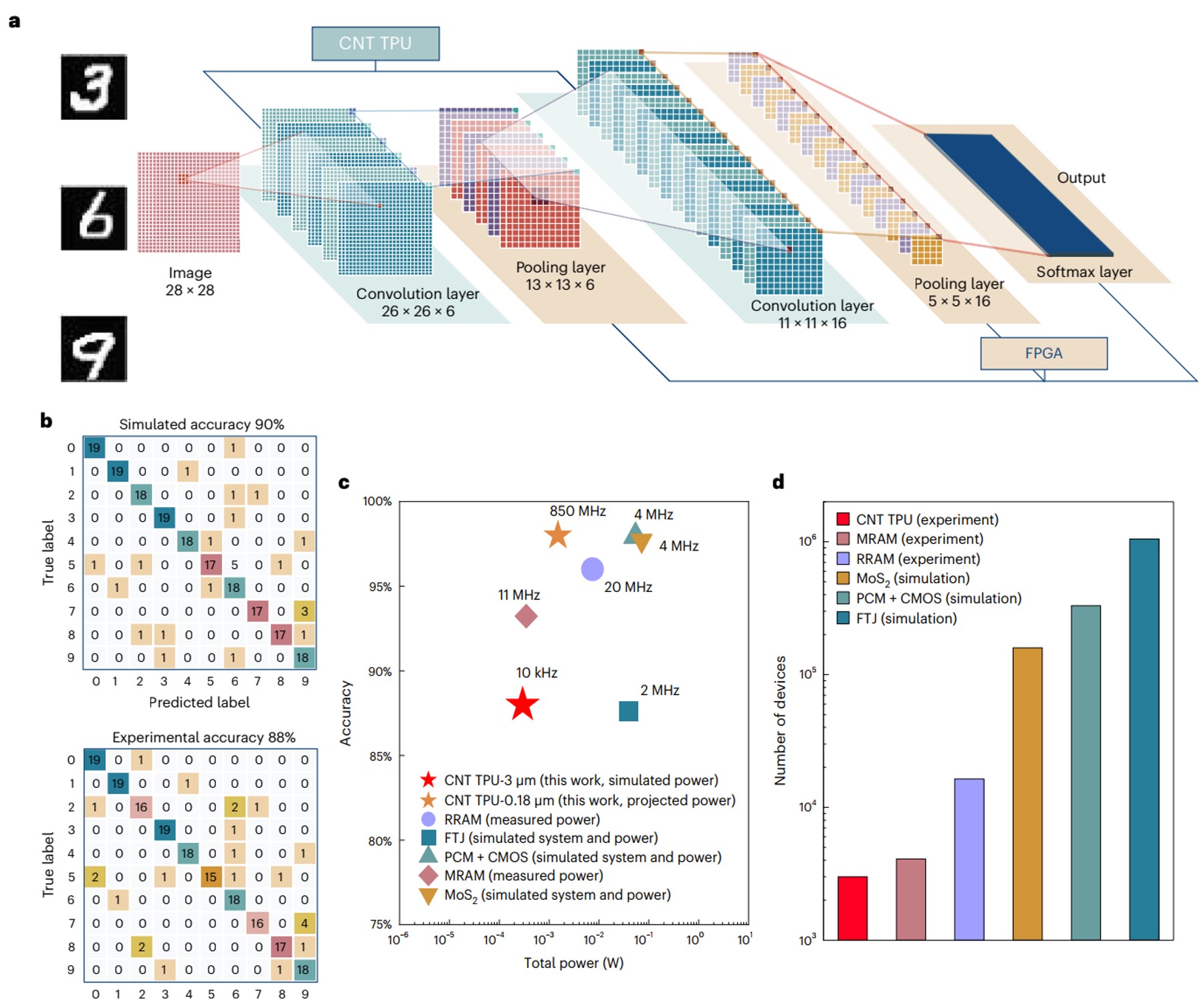
图4 卷积神经网络与手写数字识别结果
面向未来AI应用场景的碳基神经网络加速芯片,具有更强的算力和更高的能量效率。进一步提升工艺水平,缩减器件尺寸,可使用180 nm碳基技术进行流片加工。仿真结果表示,碳基神经网络加速芯片可在1 V电压下工作,可运行的最高主频为850 MHz,能效可以达到1TOPS/w,远高于其他技术,充分证明了碳基集成电路在未来高能效运算芯片领域的应用潜力。
相关研究成果以题为“碳纳米管张量处理器”(A carbon-nanotube-based tensor processing unit)的论文,于7月22日在线发表于《Nature Electronics》。宝威体肓官网、碳基电子学研究中心的司佳助理研究员为该论文的第一作者,彭练矛院士和张志勇教授为通讯作者,北京邮电大学张盼盼特聘研究员为共同第一作者,合作单位包括北京邮电大学集成电路学院、湘潭大学湖南先进传感与信息技术创新研究院和北京元芯碳基集成电路研究院。
上述研究得到了国家重点研发计划、北京市重点研发计划、国家自然科学基金和宝威体肓官网微纳加工实验室的支持。
原文链接:https://www.nature.com/articles/s41928-024-01211-2
